Czym jest BoostFS?
Niedawno wprowadzona nowość w portfolio Data Domain to możliwość dedupliakcji na źródle dla wszystkich systemów backupowych, aplikacji, baz danych, skryptów itp. Ale nim przejdziemy do dokładnego opisu BoostFS, zaczniemy od wytłumaczenia czym w ogóle jest deduplikacja oraz deduplikacja na źródle.
Od paru lat na rynku wyraźnie widać wzrost ilości danych do backupu. Stawia to przed administratorami systemów backupowych nowe wyzwania. Większa ilość danych oraz ograniczenia okien backupowych sprawiają iż tradycyjne metody backupu stają się nieefektywne oraz kosztowne. Co to jest i jak wygląda deduplikacja oraz jakie są jej atuty w przypadku DELL/EMC?
Deduplikacja danych jest w pewnym sensie rodzajem “globalnej kompresji” wyszukującej podobieństwo w elementach backupowanego zbioru. Biorąc pod uwagę fakt iż konkretny blok danych zapisany jest na dysku tylko raz (a nie np. 30 razy) bez wątpienia zmniejsza zapotrzebowanie na pojemność dyskową. Możemy wyróżnić kilka typów deduplikacji, a prościej mówiąc to parę mechanizmów jej wykonywania:
- Deduplikacja plikowa (file deduplication) – najprościej można ją wytłumaczyć jako możliwość systemu do weryfikacji i składowania tylko jednej wersji powtarzających się plików.
- Deduplikacja ze stałym blokiem (fixed deduplication) – zdolność systemu dzielenia danych na bloki o stałej długości, ich weryfikacji i składowania tylko unikalnych bloków.
- Deduplikacja ze zmiennym blokiem (Variable-Length Deduplication) – najbardziej efektywna, pozwala na dzielenie danych na bloki o zmiennej długości 4KB-12KB oraz weryfikację i zapis unikatowych bloków.
- Deduplikacja na urządzeniu docelowym – algorytm wykonujący deduplikację znajduje się na urządzeniu, na którym przechowywane będą unikatowe bloki. Minusem tej metody jest, duża utylizacja sieci IP, FC, całość backupu, wszystkie bloki przesyłane są do urządzenia.
- Deduplikacja na źródle – algorytm wykonujący deduplikację pracuje na zabezpieczanej maszynie, wykonując weryfikację unikalnych bloków bezpośrednio na niej ze zmiennym blokiem o długości od 4KB do 12KB. Tu właśnie należy wpisać oprogramowanie DELL/EMC Data Domain Boost. Zwiększa ono możliwości optymalizacyjne rozwiązań deduplikatora. DD Boost znacznie zwiększa wydajność dzięki rozłożeniu procesu deduplikacji pomiędzy system Data Domain oraz serwer backup'u lub aplikacje klienckie, pełniąc rolę stabilnego fundamentu umożliwiającego znaczne ograniczenie ilości przesyłanych przy kopiowaniu danych.
Obszerniejszy opis procesu deduplikacji oraz dokładne wyjaśnienie pojęć jak współczynnik deduplikacji znajduje się na naszej stronie pod adresem: http://www.storio.pl/deduplikacja.html
Czym jest zatem deduplikacja na źródle zawarta w Data Domain BOOST?
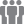
Zacznijmy od tego, jacy producenci wspierają Deduplikację na źródle poprzez BOOST:
Co takiego daje nam deduplikacja na źródle i jak wygląda? Dzięki implementacji SHA-1 (Secure Hash Algorithm) w procesorach INTEL od 2010 r. możliwe stało się zastosowanie deduplikacji na szeroką skalę. Pozwala ona na wykorzystanie istniejącego w serwerach Intel koprocesora, który zajmuje się wykonywaniem operacji potrzebnych do deduplikacji na źródłowej maszynie.

Jakie są plusy używania deduplikacji na źródle?
- Wydajność
- Największa możliwa wydajność - „obciążenie” znajduje się po stronie maszyn klienckich, przesyłana jest tylko różnica w blokach danych, więc obciążenie sieci jak i deduplikatora jest minimalne. Narzut na maszynie klienckiej wynosi około 5% utylizacji koprocesora(Intel).
- Skalowalność wydajności:
- Na różnych maszynach
- Na tej samej maszynie fizycznej
- Prędkość jest niezależna od transmisji, identyczna niezależnie czego używamy, LAN bądź SAN
- Ponad 60TB/h ciągłej transmisji backupu w środowiskach produkcyjnych
- Brak “wąskiego gardła” oraz zmniejszone obciążenie sieci
- Deduplikacja na źródle współpracuje z większością programów backupowych
- Prosta obsługa
- Równoważenie obciążenia sieciowego & automatyczny failover
- Dzieje się to dzięki grupowaniu interfejsów - w razie awarii jednego łącza, BOOST przełączy się automatycznie na inny, bez żadnych strat podczas przesyłu danych.
- Storage Unit (miejsce składowania danych na Data Domain) jest widoczne i dostępne jednocześnie poprzez LAN oraz SAN:
- Możliwość backupu poprzez SAN, później przez LAN
- Możliwość backupu poprzez LAN, później przez SAN
- Klient może backupować/odzyskiwać w tym samym czasie poprzez LAN/SAN
- Backup poprzez WAN – istnieje możliwość backup poprzez WAN, jednak aby BOOST mógł działać optymalnie sieć musi spełniać następujące wymagania:
- Możliwe opóźnienia do 200ms
- Mniejsze koszty
- Mniejsza ilość węzłów backupowych (media serwer, storage node)
- Nie potrzeba tworzyć odrębnej sieci
- Zarządzać backupem można również od strony klienta jak i od strony deduplikatora
- Funkcja Disaster Recovery zarządzana jest przez oprogramowanie backupowe
- Replikacja z granularnością do pojedynczego pliku
Źródłowa deduplikacja dostarcza nam zdecydowanie większą wydajność niż klasyczny backup. Odciąża nam istniejącą sieć, sprawia że backup wykonuje się o wiele szybciej i nie obciąża magazynu danych, w naszym przypadku Data Domain.
Skoro wiemy już co to jest deduplikacja oraz czym charakteryzuje się protokół BOOST, czas byśmy przeszli do BoostFS.
Data Domain Boost Filesystem (BoostFS) - używa tej samej technologii co BOOST, jego działanie jest identyczne i pozwala na deduplikację na źródle na maszynach klienckich. BoostFS pobiera się w postaci binariów dla systemu Linux. Jest on sterownikiem dla jądra systemu. W procesie instalacji następuje połączenie z Storage Unit na Data Domain, do którego klient na maszynie „montuje” folder znajdujący się na maszynie klienckiej (będącej źródłem). Może to być miejsce przechowywania backupu aplikacji, która nie współpracuje z BOOSTem bezpośrednio. Dla aplikacji/bazy danych/skryptu jest to folder fizycznie znajdujący się na maszynie klienckiej. BoostFS dzięki wbudowanemu mechanizmowi deduplikuje kopiowane do tego folderu pliki i przesyła unikalne bloki na macierz z funkcją deduplikacji. Plug-in emuluje strukturę drzewa katalogów na maszynie klienckiej, można je przeglądać za pomocą przeglądarek plikowych. Prawdą jest jednak, że unikalne bloki po deduplikacji zostały przesłane na Data Domaina i tam są składowane. Jak widać, za pomocą tak prostego rozwiązania jesteśmy wstanie szybko przesyłać dane na naszego Data Domaina, jednakże droga do tak efektywnego i szybkiego rozwiązania prowadzi przez zaawansowane mechanizmy całkowicie transparentne dla normalnego użytkownika maszyny klienckiej.
Schemat działania BoostFS przedstawiono na załączonym obrazie:
.jpg)
Obecnie BoostFS wspiera system operacyjny Linux. Na grudzień 2016r wspierane są następujące dystrybucje:
- Red Hat Enterpise Linux ver 6 oraz 7
- SuSe Linex Enterprise Serwer ver 11 oraz 12
- Ubuntu 14.04 i 15
BoostFS dla systemów Windows planowany jest na połowę 2017 roku wraz z pojawieniem się nowej wersji Data Domain OS.
BoostFS jest darmowy dla użytkowników, którzy posiadają licencję na BOOST i dostępny jest w wersji od Data Domain OS 6.0.
BoostFS jest plug-in’em, instalowanym na systemie operacyjnym. Pozwala nam na deduplikację na źródle dla:
- systemów backupowych (tych, które nie obsługują protokołu BOOST)
- aplikacji
- baz danych
- skryptów
Lista przetestowanych na dzień dzisiejszy aplikacji zgodnych z BoostFS:
- Aplikacje Backupowe:
- Commvault Simpana V11, V10, V9
- NoSQL Databases:
- Mongo DB v2.6, 3.0, 3.2,
- Narzędzia Backupu
- Mongodump
- OPSMgr v2.4
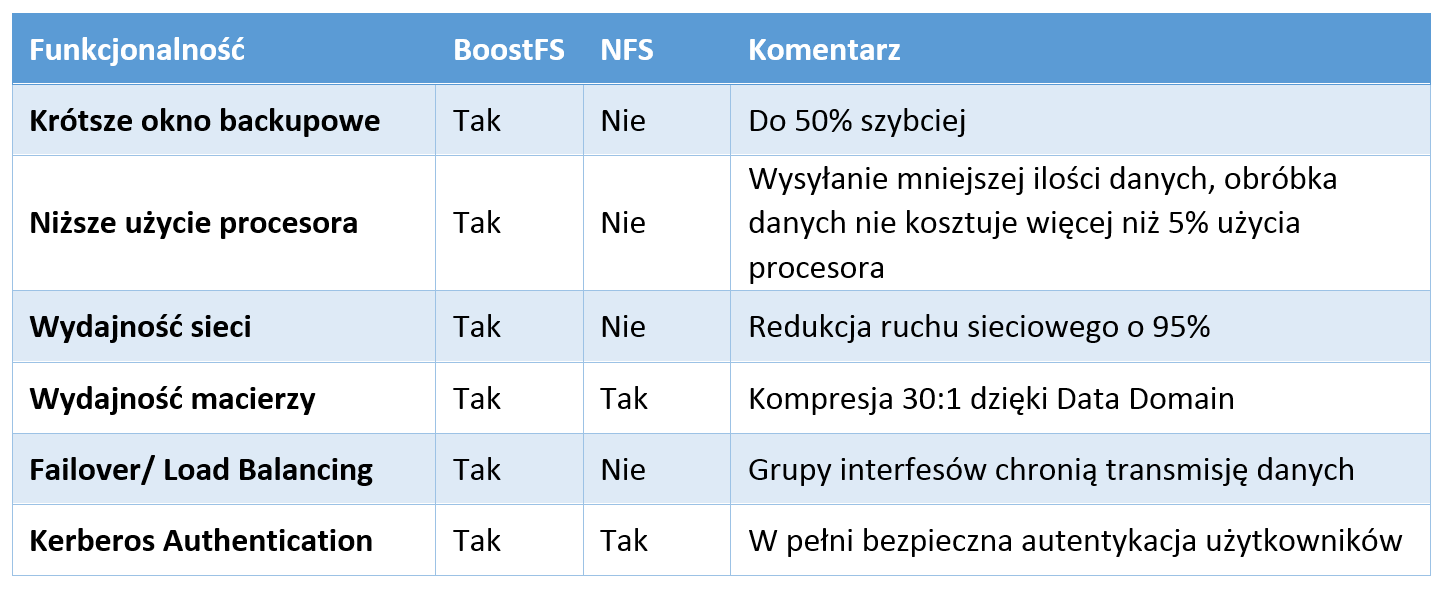
Dla systemów bazodanowych Mongo różnicę po zastosowaniu BoostFS przedstawiono w tabeli:
- MySQL v5.6, v5.7:
- Narzędzia Backupu
- MySQL Enterprise backup v5.6, v5.7
- Mydumper
- Percona XtraBackup
Podsumowywując, BoosFS pomaga w:
- Wykonaniu backupu szybkiej o 50%, zmniejszając tym okno backupowe.
- Używa do 99% mniej łącza i pozwala uniknąć kosztownych modernizacji infrastruktury sieciowej
- Daje możliwość deduplikacji na źródle przy praktycznie niezauważalnym narzucie na procesor
- Pozwala na lepszą kontrolę procesu backupu poprzez prosty i łatwy w użyciu plug-in.
- Plug-in pozwala na backup z użyciem deduplikacji na źródle z niemalże dowolnego środowiska

 +48 669 STORIO (786746)
+48 669 STORIO (786746)